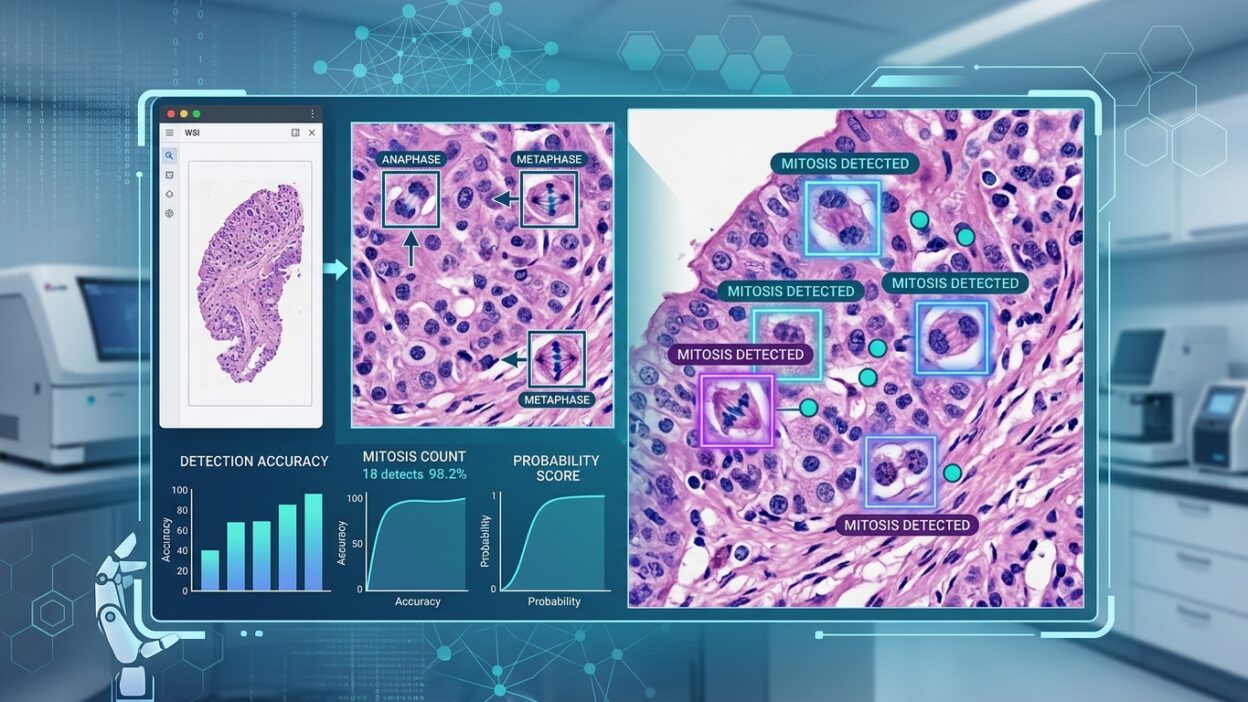
تبدو مهمة كشف الانقسامات الميتوزية مألوفة لأي اختصاصي تعامل مع grading في أورام الثدي أو الساركومات أو الأورام الجلدية. لكن الورقة الجديدة حول تحدي MIDOG 2025 تضع سؤالاً أدق من سؤال الدقة التقنية المعتاد: كيف يتصرف النموذج عندما ينتقل من hotspot مختار بعناية إلى نسيج عشوائي أو منطقة مليئة بمشتبهات بصرية؟
هذا السؤال يهم الممارسة اليومية أكثر من كثير من الجداول التي تملأ أوراق الذكاء الاصطناعي. في المختبر الحقيقي، لا تأتي الشريحة كمشهد مثالي. هناك اختلاف في النوع الورمي، النوع الحيواني في بعض مجموعات التطوير، جهاز المسح، جودة القطع، كثافة الخلايا، الالتهاب، النخر، وتشابه بعض النوى مع الانقسامات. لذلك اختار منظمو MIDOG 2025 أن يقيسوا قدرة النماذج على العمل في ظروف أقرب إلى الفوضى التي يعرفها اختصاصيو الباثولوجيا.
ما الذي اختبره MIDOG 2025؟
الورقة منشورة على arXiv بتاريخ 5 حزيران 2026، بعنوان Mitosis Detection in the Wild: Multi-Tumor and Context-Aware Generalization in the MIDOG 2025 Challenge. شارك في العمل Marc Aubreville وزملاء من فريق واسع، وركز التحدي على مسارين: كشف الأجسام الميتوزية، ثم تصنيف الانقسامات إلى طبيعية وغير نمطية.
مجموعة الاختبار ضمت 365 حالة عبر 12 نوعاً ورمياً بشرياً وكلبياً وقطياً، مع شرائح رقمية من منصات مسح متعددة. هذا التصميم يمنع النموذج من النجاح عبر حفظ نمط واحد. كما أن مناطق التقييم لم تقتصر على hotspots منتقاة، بل شملت مناطق عشوائية تمثل أجزاء من WSI ومناطق صعبة غنية بالمشتبهات التي قد تزيد الإيجابيات الكاذبة.
في مسار الكشف شاركت 18 جهة، ووصل أفضل أداء إلى F1 يساوي 0.740. في مسار تصنيف الانقسامات غير النمطية، وصلت أفضل نتيجة إلى balanced accuracy يساوي 0.908 عبر 21 مشاركة. هذه أرقام جيدة، لكنها تصبح أكثر فائدة عندما ننظر إلى أين فشلت النماذج، لا أين نجحت.
الرقم الذي يجب أن يوقفنا
أهم نتيجة في الورقة هي تراجع الأداء عند الانتقال من مناطق hotspot التقليدية إلى مناطق صعبة. معدل الإيجابيات الكاذبة ارتفع بنسبة 208 في المئة في تلك المناطق. هذا الرقم يشرح مشكلة عملية يعرفها من يراجع الحالات: الخلية التي تبدو كميتوز في مجال غني بالمشتبهات قد تكون apoptotic body أو نواة منسحقة أو artefact أو خلية التهابية بطريقة عرض خادعة.
إذا كان النظام يعطي عدداً أعلى من الانقسامات في المناطق الصعبة بسبب ضجيج بصري، فإن أثره لا يبقى داخل لوحة تقييم بحثية. قد يغير ذلك درجة الورم، أو يرفع قلق الفريق السريري من عدوانية الحالة، أو يفرض مراجعة إضافية على اختصاصي الباثولوجيا. لذلك لا يكفي أن تقول الشركة أو الورقة إن النموذج نجح على مجموعة اختبار عامة. يجب أن نعرف تركيب تلك المجموعة، وطريقة اختيار الحقول، وما إذا كانت تحتوي على مناطق تشبه الحالات التي تسبب خلافاً بين الزملاء في العمل اليومي.
اختلاف النوع الورمي ليس تفصيلاً صغيراً
أظهرت الورقة أيضاً أن الأداء اختلف بين الأنواع الورمية الاثني عشر. هذه نقطة حاسمة عند التفكير في إدخال أداة عد الانقسامات إلى مختبر تشخيصي. النموذج الذي يتعلم من سرطان ثدي أو ورم جلدي شائع قد يتعثر عندما يرى ورماً نادراً أو عالي التغاير أو ذا خلايا شديدة pleomorphism. هنا تظهر قيمة اختبار متعدد الأورام، لأن المتوسط العام قد يخفي جيوب فشل واضحة.
بالنسبة لاختصاصي الباثولوجيا، هذا يعني أن تقرير التحقق الداخلي يجب أن يسأل عن كل استعمال مقصود على حدة. هل سيستخدم النموذج لدعم grading في نوع ورمي محدد؟ هل سيعمل كأداة triage؟ هل سيعرض نقاطاً ساخنة فقط، أم سيقترح عدداً نهائياً؟ كل إجابة تغير مستوى المخاطرة وتغير ما يجب قياسه قبل السماح للأداة بالدخول إلى سير العمل.
التجميع ساعد، واختبار الوقت لم يضف الكثير
حللت الورقة أثر ensembling وtest-time augmentation. التجميع أعطى تحسناً ثابتاً تقريباً، بزيادة وسطية قدرها 1.5 نقطة مئوية في F1 لمسار الكشف و1.3 نقطة مئوية في balanced accuracy لمسار التصنيف. أما test-time augmentation فلم يضف تحسناً ذا قيمة واضحة.
هذه النتيجة مفيدة للفرق التي تشتري أو تطور أدوات داخلية. تحسين الأداء عبر تجميع عدة نماذج قد يأتي بثمن في زمن الاستدلال، الذاكرة، الصيانة، وتتبع النسخ. إذا كان التحسن صغيراً لكنه ثابت، فيجب وضعه مقابل الكلفة التشغيلية. أما زيادة خطوات المعالجة دون أثر واضح، فستبدو جذابة على الورق وتتحول إلى عبء في الإنتاج.
ما الذي أريد رؤيته قبل استعمال سريري؟
أول مطلب هو تقرير تحقق مفصل حسب النوع الورمي والسياق النسيجي. المتوسط العام لا يكفي. أريد رؤية الأداء في hotspots، المناطق العشوائية، والمناطق الغنية بالمشتبهات. وأريد أن أعرف أين ترتفع الإيجابيات الكاذبة، لأن هذا النوع من الخطأ هو ما يستهلك وقت المراجع ويزرع الشك في العد النهائي.
المطلب الثاني هو فصل واضح بين أداة تجذب عين الاختصاصي إلى مناطق محتملة، وأداة تنتج قياساً يمكن أن يدخل في القرار. الأولى قد تكون مقبولة بسرعة أكبر إذا كانت واجهتها صادقة ومراجعتها سهلة. الثانية تحتاج إلى تحقق أضيق، وحدود استعمال مكتوبة، ومراقبة أداء بعد الإطلاق.
المطلب الثالث يتعلق بطريقة عرض النتائج. الخرائط الحرارية وحدها لا تحل المشكلة إذا لم تسمح للمستخدم برؤية كل جسم محسوب، قبول أو رفض العلامات بسرعة، ومقارنة العد مع مناطق مختارة يدوياً. الأداة الجيدة في المختبر تقلل العمل المكرر وتعرض مصادر الخطأ بوضوح، بدلاً من الاكتفاء بعرض بصري مبهر.
قراءة عملية للورقة
قيمة MIDOG 2025 أنها تدفع تقييم كشف الانقسامات نحو أسئلة أقرب إلى التشخيص. الورقة لا تقول إن المهمة حلت. بالعكس، تظهر أن الأداء يتغير مع السياق النسيجي وأن المناطق الصعبة تكشف عيوباً قد لا تظهر في اختبار مريح. هذا النوع من التقييم يخدم الباثولوجي لأنه يحول النقاش من سؤال عام عن الذكاء الاصطناعي إلى سؤال محدد: هل يعمل هذا النظام في الحالة التي سأضع اسمي عليها؟
أفضل استخدام فوري لهذه الورقة هو كقائمة أسئلة عند مراجعة أي منتج أو مشروع بحثي لعد الانقسامات. اسأل عن تنوع الأورام، اختيار الحقول، أثر المشتبهات، أجهزة المسح، زمن الاستدلال، وطريقة مراجعة العلامات. إذا لم تكن هذه الأجوبة موجودة، فالأداء المعلن يبقى ناقصاً مهما بدا الرقم مرتفعاً.
المصدر: arXiv:2606.07368v1