Pathology News reported on ClinSegAI, a research framework from a team at Binghamton University that improves cell segmentation outputs in digital slides after they leave a foundation model. The original paper was published in Computers in Biology and Medicine under the title: ClinSegAI: A post-processing framework for superior histopathology segmentation accuracy, radiomics feature preservation, and quantitative analysis.
The point is not just another tool name. For pathologists, the closer issue is that a segmentation model can look visually convincing, then fail when nuclear and cytoplasmic borders are converted into digital measurements. In radiomics, a small mask error carries into shape, intensity, texture, and then into any later prediction model. Segmentation should be treated as a measurement step, not as a colored overlay on a WSI.
What does ClinSegAI do?
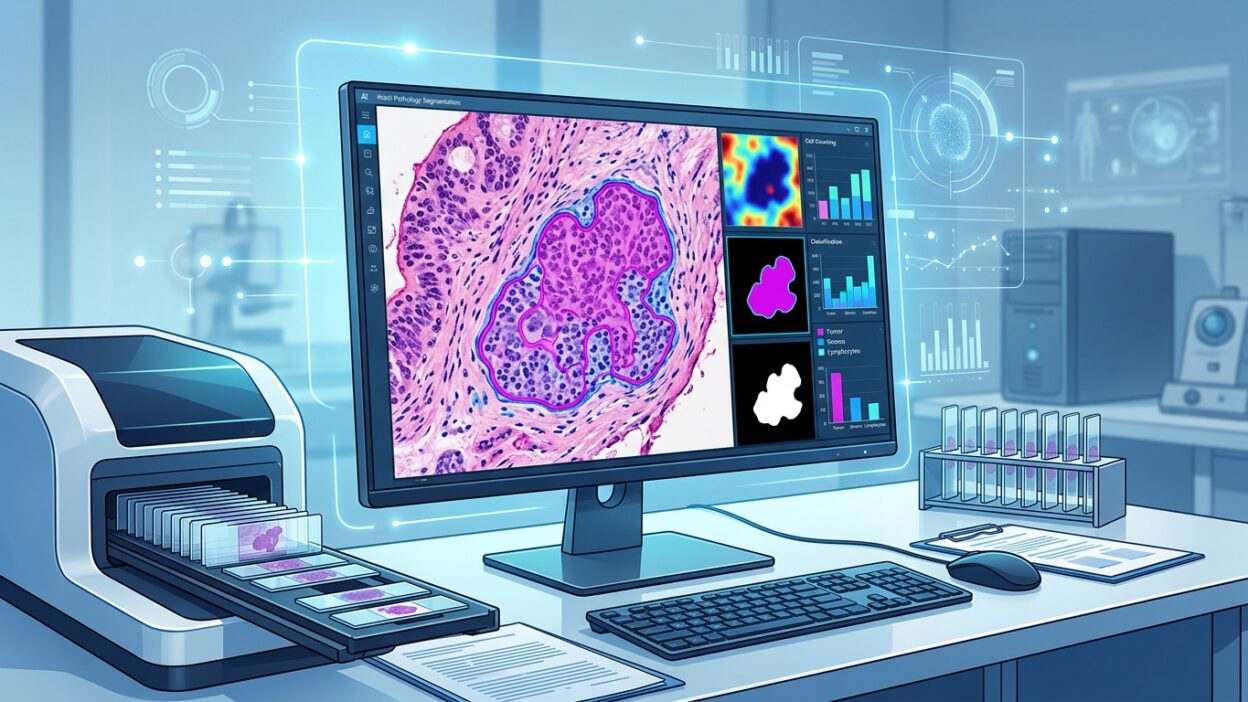
The framework uses BiomedParse to produce the initial segmentation in H&E images, then applies a post-processing correction layer to the masks. This layer refines borders and handles regions that need merging or splitting, with the aim of preserving cellular morphology more accurately. The study places this step after the model, so BiomedParse does not need to be retrained or have its weights modified.
That detail matters for laboratories. Many institutions do not have the time, data, or infrastructure to retrain large models for every project. A post-processing correction layer may be more realistic if it can be tested locally and tied to the quality system. That does not make it ready for direct clinical decision-making, but it makes the practical question more specific: can the masks be improved enough to protect the measurements that will support later analysis?
The numbers that matter to the pathologist
According to the available abstract, ClinSegAI was evaluated on lung cancer slides and other tissue types, and was compared with six segmentation methods, including traditional software and newer deep learning models. It achieved the highest mean Dice coefficient, close to 0.80, with fewer segmentation errors. It also recorded the best HD95 and ASSD results among the compared methods.
These metrics do not replace pathologist review, but they show the type of error. Dice gives a sense of overall overlap between the mask and the reference standard. HD95 and ASSD are more sensitive to border distortion and surface distances. In tumor tissue, especially when nuclear borders overlap or edges are weak because of processing or staining, the difference between a visually acceptable mask and a measurement-ready mask can be large.
The most useful part of the paper is its link between segmentation and preservation of radiomics feature distributions. The researchers examined shape, intensity, and texture features, and used comparative statistics to estimate how close they were to the reference standard. The field needs this angle more than another set of before-and-after images. The pathologist is not asking for a pretty mask. The pathologist is asking for a measurement that does not change the conclusion.
Why does this matter in the workflow?
The team interviewed 40 pathologists from academic and hospital settings. The report listed familiar needs: faster identification of regions of interest, slide-level triage, and quantitative features that may help with prediction or correlation with other data. These are not distant wishlist items. They are daily points of friction when WSI enters diagnostic or research work.
In practice, the value of any segmentation tool depends on where it enters the chain. If the tool is meant to triage tumor regions, the acceptance threshold differs from a tool that will feed a model predicting survival or treatment response. If the result will be linked to spatial transcriptomics data, a border shift or the merging of two cells can create noise that is invisible on the viewer but visible in the analysis.
Limits that should not be ignored
The news report and abstract are not enough to judge readiness for clinical use. We need to read the details of the sample, cancer types, reference-standard creation, number of reviewers, staining and scanner variation, and how lower-quality sections were handled. External testing on data from other laboratories is also needed. These are normal questions for any tool that moves close to diagnosis.
There is another point. Improving the mask does not remove the laboratory’s responsibility for quality control. If sectioning is poor, staining is unstable, or focus varies across the slide, the algorithm may hide some defects and leave others. Tools like this need a clear dashboard: the rate of rejected masks, regions of low confidence, and an auditable record when the version or processing settings change.
The practical reading
ClinSegAI points to a real problem in digital pathology: the gap between a model that produces a mask and a quantitative result that can be defended. For that reason, it is useful news for pathologists working with AI in research projects or institutional evaluations. The question when evaluating similar tools should be specific: what happens to the measurements after correction? Does the analytical decision improve, or only the appearance of the image?
If independent studies show that post-processing correction preserves radiomics features across different scanners, stains, and laboratories, this type of layer may become an important part of WSI analysis pipelines. Until then, ClinSegAI offers a practical lesson: trust in AI does not start with the model. It starts with the measurement the model produces, and with the laboratory’s ability to review and trace that measurement.
Source: Pathology News.