هذا الموضوع ظهر في دورة الأخبار سابقا، لكنه متداول بما يكفي ليستحق العودة إليه من زاوية مهنية مختلفة. الخبر يدور حول نظام PRET الذي طوره فريق تقوده جامعة هونغ كونغ للعلوم والتكنولوجيا HKUST، بالتعاون مع Guangdong Provincial People’s Hospital وHarvard Medical School. الفكرة الأساسية واضحة: نموذج لتحليل الشرائح الرقمية يستطيع التعامل مع أكثر من نوع سرطان ومهمة تشخيصية بعد الرجوع إلى عدد صغير جدا من الشرائح المعلّمة، من شريحة واحدة إلى ثماني شرائح، من دون تدريب إضافي خاص بكل مهمة.
بالنسبة لاختصاصي علم الأمراض، قيمة الخبر لا تكمن في العبارة التسويقية حول نموذج جاهز للتوصيل والاستخدام. القيمة الحقيقية في السؤال الذي يفرضه PRET: هل يقترب الذكاء الاصطناعي في علم الأمراض من نمط عمل أكثر شبها بالاستشارة الخبيرة، حيث تكفي أمثلة قليلة لتوجيه القراءة، أم أن هذه النتائج ستبقى مرتبطة بمجموعات اختبار مضبوطة لا تشبه ضغط العمل اليومي؟
ما الذي فعله نموذج PRET؟
يعتمد PRET على فكرة التعلم من السياق، وهي فكرة معروفة في نماذج اللغة، ونقلها الباحثون إلى صور علم الأمراض. بدلا من تدريب نموذج جديد أو ضبط نموذج قائم لكل سرطان أو مهمة، يتلقى النظام أمثلة معلّمة قليلة أثناء مرحلة الاستدلال، ثم يستخدمها مرجعا فوريا للتعامل مع الحالة المطلوبة.
المهام المذكورة في التقرير تشمل كشف السرطان، التصنيف الفرعي للأورام، وتجزئة الورم على الشرائح. هذا التنوع مهم لأن كثيراً من أدوات الذكاء الاصطناعي في علم الأمراض تقدم أداء جيدا في مهمة ضيقة، ثم تفقد جزءا كبيرا من قيمتها عند نقلها إلى نوع ورم آخر أو بروتوكول تحضير مختلف أو عينة من مركز آخر.
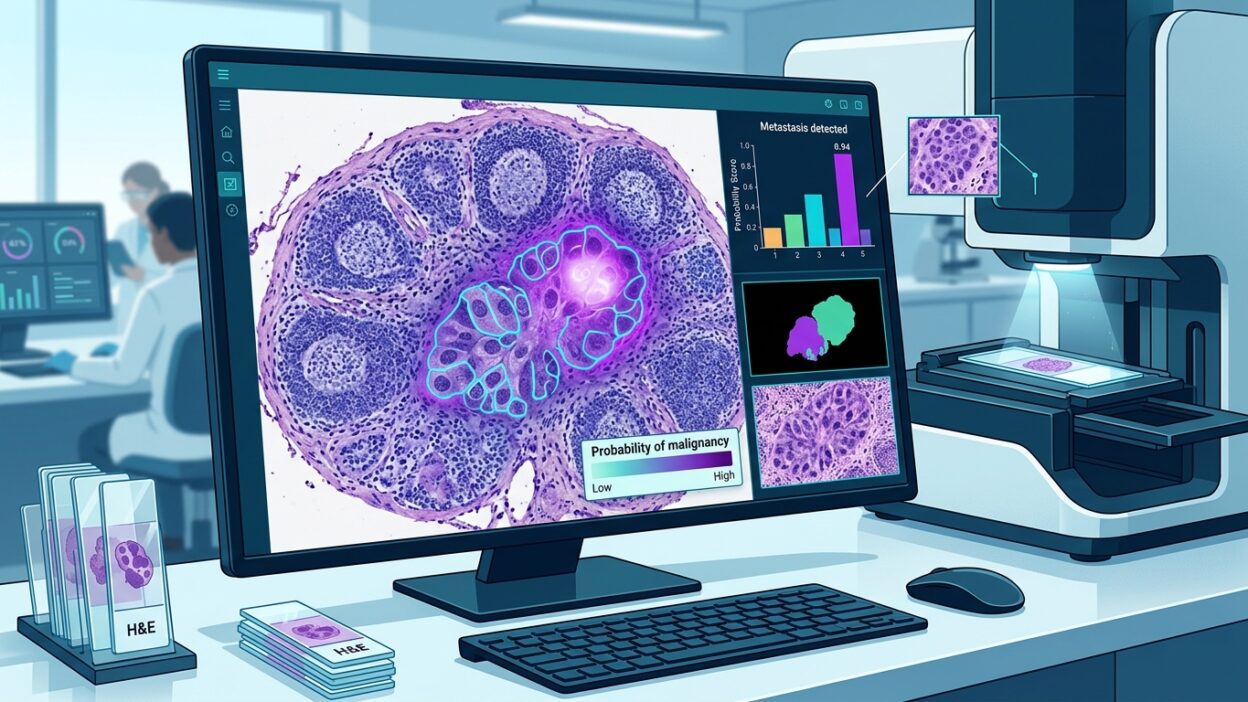
اختبر الفريق النظام على 23 مجموعة معيارية دولية من الصين والولايات المتحدة وهولندا، وغطت هذه الاختبارات 18 نوعا من السرطان. بحسب التقرير، تفوق PRET على الطرق المقارنة في 20 مهمة، وتجاوزت قيمة AUC حاجز 97% في 15 مهمة. هذه أرقام قوية، لكنها تحتاج إلى قراءة حذرة. AUC المرتفع لا يخبرنا وحده بمكان الخطأ، ولا يوضح أثر العتبة المختارة على الحساسية والنوعية، ولا يكشف بالضرورة أداء النموذج في الشرائح الرديئة أو العينات ذات القطع المحدود أو الحالات المختلطة.
النقائل العقدية: الرقم الذي سيهم الممارسين
أبرز نتيجة في الخبر تخص كشف النقائل في العقد اللمفاوية. ذكر التقرير أن PRET حقق AUC يقارب 98.71% باستخدام ثماني شرائح فقط، بينما بلغ متوسط أداء 11 اختصاصي علم أمراض في المقارنة نحو 81%. هذه الفجوة لافتة، لكنها يجب ألا تقرأ خارج تصميم الدراسة.
كشف النقائل العقدية مهمة مناسبة لاختبار أنظمة المساعدة الرقمية لأنها تجمع بين عبء فحص مرتفع وخطر سريري واضح عند إغفال البؤر الصغيرة. ومع ذلك، يعرف الممارس أن الصعوبة لا تتوزع بالتساوي. هناك شرائح يمكن حسمها بسرعة، وهناك بؤر صغيرة أو مناطق التهابية أو شوائب تقنية ترفع احتمال الالتباس. لذلك، السؤال العملي يجب أن ينتقل من مقارنة المتوسطات إلى تفاصيل الخطأ: أين أخطأ النموذج، وما حجم الأخطاء، وهل كانت أخطاؤه من النوع الذي يستطيع اختصاصي علم الأمراض اكتشافه بسهولة داخل سير العمل؟
إذا كان النظام يعمل كفرز أولي أو كطبقة تنبيه داخل عارض الشرائح، فقد تكون فائدته مختلفة تماما عن استخدامه كقارئ مستقل. في الحالة الأولى، يمكن أن يقلل زمن البحث في الشرائح الكبيرة ويجذب الانتباه إلى مناطق محددة. في الحالة الثانية، ترتفع متطلبات التحقق والحوكمة وتفسير القرار.
النماذج قليلة العينات قد تغير حسابات التبني
أحد أسباب بطء إدخال الذكاء الاصطناعي إلى المختبرات هو كلفة البيانات. جمع عشرات الآلاف من الصور، ووسمها، ومراجعتها، ثم إعادة تدريب النموذج لكل مهمة، مسار طويل ومكلف. لا يناسب ذلك كل مختبر، ولا كل نظام صحي، ولا كل سرطان نادر.
لذلك تبدو فكرة الاعتماد على أمثلة قليلة جذابة. مختبر يملك عددا محدودا من الحالات الموثقة قد يستطيع اختبار أداة بسرعة أكبر. مركز في منطقة محدودة الموارد قد لا يحتاج إلى بناء مجموعة ضخمة قبل أن يبدأ تقييم فائدة النموذج. لكن الجاذبية هنا لا تكفي. الأمثلة القليلة نفسها يجب أن تكون ممثلة. شريحة واحدة سيئة الاختيار قد توجه النظام في اتجاه خاطئ، وثماني شرائح قد لا تغطي تنوع التحضير والنمط النسيجي والاختلاف بين الماسحات.
هذا يضع مسؤولية جديدة على اختصاصي علم الأمراض. سيتجاوز دوره ضغط زر التشغيل إلى اختيار الأمثلة المرجعية، وتعريف الحالات المقبولة، وتحديد حدود استخدام النموذج. الأداة التي تتعلم من أمثلة قليلة تجعل جودة تلك الأمثلة جزءا من جودة القرار النهائي.
ما الذي يجب طلبه قبل أي استخدام سريري؟
قبل التفكير في اعتماد نموذج مثل PRET، أرى أن الاختبار المحلي غير قابل للاختصار. يحتاج كل مختبر إلى معرفة أداء النظام على شرائحه هو، لا على مجموعة معيارية فقط. اختلاف التثبيت، التقطيع، الصبغ، المسح، وضغط الصورة قد يغير السلوك بدرجة تؤثر على الثقة.
الأمر الثاني هو تحليل الأخطاء. المتوسطات لا تكفي. نحتاج إلى أمثلة للحالات التي أخفق فيها النظام، وحجم البؤر التي فاتته، وأنواع الأنسجة أو الشوائب التي رفعت الإيجابيات الكاذبة. من دون ذلك، يبقى الرقم العام جيدا للعرض العلمي، لكنه غير كاف لتغيير مسار العمل.
الأمر الثالث هو مكان الأداة داخل المختبر. إذا استُخدمت في فرز الشرائح، يجب قياس أثرها على زمن القراءة وعدد المناطق التي يراجعها الطبيب ونسبة الحالات التي تتطلب رجوعا إضافيا. إذا استُخدمت في اقتراح تصنيف فرعي أو تجزئة ورمية، يجب ربطها بمعايير واضحة للمراجعة البشرية والتوثيق داخل التقرير.
قراءة متوازنة للخبر
PRET يقدم اتجاها مهما في علم الأمراض الرقمي: نماذج أقل اعتمادا على التدريب الطويل لكل مهمة، وأكثر قدرة على الاستفادة من أمثلة مرجعية قليلة. هذا قد يكون مناسبا خصوصا للمهام التي تتكرر كثيرا وتستهلك وقتا، مثل فحص العقد اللمفاوية، أو للمهام التي يصعب فيها جمع بيانات ضخمة.
لكن القوة المعلنة في الدراسة لا تلغي الأسئلة اليومية. هل يحافظ النموذج على أدائه مع شرائح من مختبرات صغيرة؟ هل يتأثر بنوع الماسح؟ هل يستطيع التعامل مع التلوين غير المثالي؟ هل يعطي الطبيب خريطة مفهومة للقرار أم يكتفي بنتيجة رقمية؟ هذه الأسئلة هي التي ستحدد قيمة النظام في المختبر، لا العنوان وحده.
الخلاصة المهنية بسيطة: PRET يدفعنا إلى رفع مستوى الأسئلة التي نطرحها على أدوات الذكاء الاصطناعي، مع إبقاء اختصاصي علم الأمراض في مركز القرار. الأرقام المنشورة قوية، وموضوع النقائل العقدية يستحق المتابعة، لكن الطريق إلى الاستخدام السريري يمر عبر تحقق محلي صارم، وتحليل أخطاء شفاف، وتعريف واضح لدور الطبيب في كل خطوة.
المصدر: Pathology News